The SyntaxGym architecture¶
This page describes the standardized architecture of SyntaxGym used to represent and evaluate targeted syntactic evaluations. This page should be a useful reference for those looking to interpret SyntaxGym results, or to develop their own evaluation experiments.
SyntaxGym represents targeted syntactic evaluation experiments as test suites. Test suites evaluate language models’ knowledge of some particular grammatical phenomenon. Their structure should be familiar to those experienced in psycholinguistic experimental design.
In this document, we’ll use subject–verb agreement as a running example of a grammatical phenomenon of interest. Concretely, we want to test models’ knowledge of a few critical grammaticality contrasts (here “*” indicates an ungrammatical sentence):
The farmer near the clerks knows many people.
* The farmer near the clerks know many people.
The farmers near the clerk know many people.
* The farmers near the clerk knows many people.
A language model that has learned the proper subject–verb number agreement rules for English should assign a higher probability to the grammatical verbs in (1) and (3) than to the ungrammatical verbs in (2) and (4).
The structure of test suites¶
The following figure visualizes a simple test suite for subject–verb number agreement as a table:
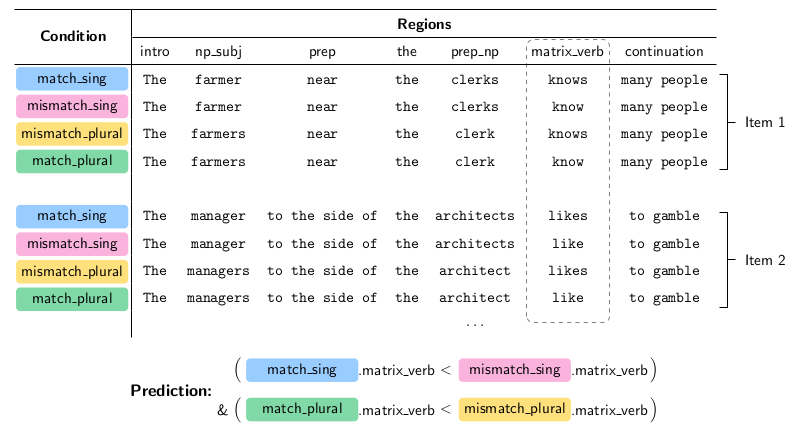
We’ll reference this figure as we describe the components of a test suite from the bottom-up.
Regions¶
The atomic unit of a test suite is a region: a (possibly empty) string, such as
the matrix_verb region in the figure above. Regions can be concatenated to
form full sentences. Note that regions can contain multiple tokens.
Conditions¶
Regions vary systematically across experimental conditions, shown as colored
pill shapes in the above figure. Here the matrix_verb and np_subj
regions vary between their respective singular and plural forms, as described
by the condition name.
Items¶
Items are groups of related sentences which vary across experimental conditions. An item is characterized by its lexical content and takes different forms across conditions. In the above figure, items are grouped together in vertical blocks of rows.
Predictions¶
Test suites are designed with a hypothesis in mind: if a model has correctly
learned some relevant syntactic generalization, then it should assign higher
probability to grammatical continuations of sentences. Test suite predictions
operationalize these hypotheses as expected inequalities between model
surprisal statistics in different experimental regions conditions (i.e.,
between cells within item blocks in the above figure). The SyntaxGym standard
allows for arbitrarily complex disjunctions and conjunctions of such
inequalities. The above figure shows a prediction with two inequalities between
model surprisals at matrix_verb across two pairs of conditions.
Making your own¶
Now that you understand the basic structure of a test suite, see Test suite JSON representation for information on how to write your own suites in JSON format.